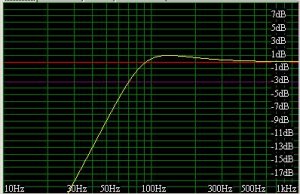
Totte. Luringen. Nei det er nok ikke så ille som at de har glattet dB verdiene her. Men det er en bra innfallsvinkel til poenget mitt.
Roald,
Jeg tenker på noe annet, men jeg tror det du sier stemmer.
Veggen,
Dippen ja. Peaken nei.
Valentino,
Ett poeng av 1,5 mulige. Gratulerer med seieren.
Hvis vi ser litt grovt på det så faller den glattede kurven systematisk mer enn den uglattede. I hvert fall fra mitt ståsted 8)
Ved 20 Hz er det ganske nøyaktig 10 dB mellom de to kurvene. Går man ned 10 dB ved 20 kHz så er man ganske langt nedi kamfilteret. Lest som et forsøk på å vise hvordan det låter så blir dette feil. Dette kan vi kalle den psykoakustiske feilen.
Men det er en annen side også. Som er ren fysikk og matematikk. Impulseresponsen viser hva som skjer med lyden over tid. Og ettersom impuls og frekvens bare er to ulike måter å presentere samme informasjon på, så kan det samme sies om frekvensresponsen (amplitude + fase). Det er bare en catch her. Og det er at frekvensresponsen viser ikke alltid det vi tror den viser. På overflaten viser den kun hvor kraftig en tone på en bestemt frekvens blir gjengitt. Det vi ikke umiddelbart ser er hvor lenge tonen må vare før den låter slik, hva slags nivåforløp den har fram til dette tidspunktet og hva som skjer i det vi slår av høyttaleren og rommet spiller videre. Når fasegangen også er med så har man hele det tidsmessige forløpet godt maskert i to frekvensplott, men det er vel ingen som har Fourier transformasjonen så godt under huden at de kan se dette forløpet.
For å sette det på spissen kan man gjerne Fouriertransformere hele Beethovens 9. symfoni til frekvens og fase. Litt tungt regnemessig er det, men man mister ikke noe av musikken. Hvis noen som studerer dette plottet får tårer i øynene så er de sannsynligvis svært musikalse og nerdete og smarte av en helt annen verden. Eller kanskje de bare har pollenallergi. ;D
Punkt for punkt i den velkjente frekvensresponsen viser en steady-state respons. Den viser lydtrykket på toner med en uendelig lang varighet. Vi tenker oss gjerne at når vi spiller av en tone over husalteret så fungerer omtrent på dette viset:
Altså at en tone med en bestemt varighet som har et rimelig konstant lydtrykk som er i tråd med det frekvensresponsen viser. Og da er jo steady state helt OK. Men noen ganger kan det ta ganske lang tid før lydtrykket bygger seg opp:
I disse figurene varer tonen 200 millisekunder. Det hadde nok fortsatt å stige en stund til på denne frekvensen hvis tonen hadde vart lengre. At lydtrykket også er en funksjon av tid er kanskje ikke noe man tenker over hele tiden. Bortsett fra waterfall plots, da. Men de forteller jo bare om etterklangen, når høyttaleren har sluttet å spille. Etterklangen har jo betydning for taletydeligheten. Og den generelle maskeringen som etterklangen kan utsette musikken for. Men jeg tror det har mer å si for lydkvaliteten i de fleste rom hvordan lydnivået varierer mens lyd spilles enn hvordan den dør ut etter at lyden er slått av.
Noen vil kanskje tenke på dette som non-lineariteter og egenskaper som varierer over tid. Men dette er effekter av lineære og tidsinvariate systemer. Alt ligger i impulsresponsen og kan hentes ut derfra med de rette analysemetoder. Det er bare effekten som kan virke tidsavhengig og nonlineær. Effekten av at direktelyden blander seg med sine egne refleksjoner.
Det som kanskje er aller mest interessant er hva som skjer når det er en kansellering:
Da får man først en direktelyd med et ganske anstendig lydnivå. Kanselleringer kommer jo med en liten forsinkelse. Så kommer den kansellerte tilstanden med kraftig dempet nivå. I det tonen stilner i høyttaleren får vi en ny peak fordi romrefleksjonene nå får råde grunnen alene en stakket stund. Vi får en ny og kraftig peak. Den siste peaken vil selvfølgelig være ca 180* fasedreid i forhold til den første.
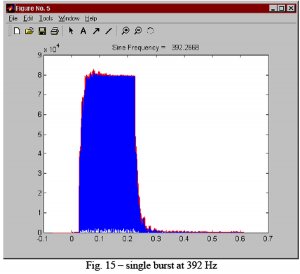
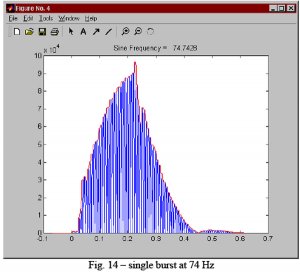
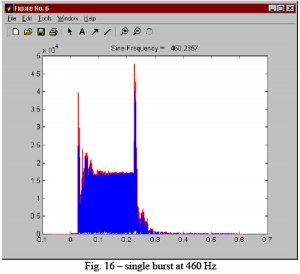
Alle disse figurene er fra måling i bil.
Jeg har gjort en del liknende simuleringer i vanlige rom. De fleste frekvenser oppfører seg rimelig ryddig og pent. Men på vanskelige frekvenser kan det nesten se ut som en etappe i Tour de France. Det er mye rart som kan skje på vei mot den steady state tilstanden som frekvensplottet viser. Og oppholdsrom er mye større enn biler så det tar ofte lengre tid før alle refleksjoner har satt inn støtet sitt. Når det er mye berg- og dalbane i frekvensresponsen så kan dere trygt gå ut fra at det skjer rare ting i tidsdomenet også.
Disse illustrasjonene er hentet fra en artikkel av Angelo Farina. Og her driver han med bil-hifi. Mao en akustisk worst case. Vanlig 1/3 oktavs glatting og liknende samsvarer ikke optimalt med den subjektive lydkvaliteten i bil, for å si det forsiktig. Det fungerer nok atskillig bedre i vanlige oppholdsrom - som regel. Men også her vil det ofte være vesentlige avvik her og der som kan forkludre eventuelle forsøk på å fikse problemet med digital signalbehandling. Om man legger feil kurve til grunn.
Det er mye i Farinas forskning som tyder på at dett er den kraftigste delen av gjengivelsen som påvirker lydoppfattelsen mest. Spikene på vei inn i og ut av en kansellering påvirker hvordan vi oppfatter lyden mer enn den lyden som spilles mens kanselleringen pågår. Farina m.fl. gjorde lyttetester i bil der de sammenliknet hvordan det låter når de korrigerer basert på stasjonære verdier (tilsvarende 1/3 oktavs kurven ovenfor) og "overshoot" (maksverdiene ved hver frekvens. Konklusjonen kan ikke sies å være bunnsolid ut fra vitenskapelige kriterier, men det er troverdighet i at overshoot plottet samsvarer bedre med hvordan lydkvaliteten oppleves enn det 1/3 oktav eller 1/6 oktav osv. gjør. Det er også mye psykoakustisk forskning som kan forklare hvorfor det er slik. Maskeringseffekter står veldig sentralt i denne forskningen. Mer fokus på hva som maskeres enn hva som høres, for å si det på den måten.
De som driver og roter med MP3 og andre former for informasjonsreduksjon snur jo hver sten for å finne maskert lyd som de kan fjerne uten at lydkvaliten reduseres "nevneverdig"

. Men vi som vil høre alt kan bruke kunnskapen om de samme maskeringseffekter til å minimalisere den maskering som skjer i lytteposisjonen.
Det er mye som tyder på at en kort spike i innledningen til en kansellering gjøre "voksen manns jobb" på maskeringsfronten. Den er jo selvsagt også hørbar i seg selv også
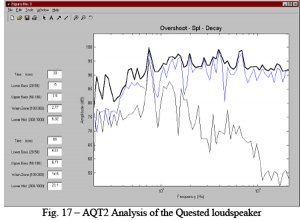
Her er nok en kurve fra samme paper, der man viser frekvensrespons, overshoot respons. Og respons etter 30 millisekunder. Den siste har tilknytning til artikulasjon og er mer relevant for bil enn større rom der det er mer vanlig å operere med 60 millisekunder.
Som dere ser, ligger overshoot-responsen og cruiser helt i toppen på kamfilteret hele veien. Og mange av kanselleringene er redusert til et moderat søkk. Hvis man så tar og 1/3 glatter denne så får man et helt annet resultat enn den som Linkwitz produserte ovenfor. Dersom Farina har rett (og det har han ofte hatt), så gir denne overshoot responsen en mye mer korrekt grafisk fremstilling av hva vi hører fra godstolen enn den vanlige responsen. Dette er en av hovedgrunnene til at jeg foretrekker å se på ufiltrerte responser for å vurdere lydkvalitet. Glattede kurver vises jo i hytt og pine, men er de filtrert så vet man strengt tatt ikke hva man ser på.
Det er en ganske godt etablert myte, både blant DSP skeptikere og en del DSP tilhengere at (det er OK å dempe resonnanstopper, men at )det ikke er OK å korrigere for dipper i responsen. "Det går ikke an". Ja særlig! Det går utmerket an å heve en dipp 10-20 dB. Og de fleste anlegg tåler det også. Men forskningen til Farina forklarer hvorfor det kan gå galt når man forsøker å korrigere dipper basert på vanlig frekvensrespons: Man korrigerer en stasjonær dipp og introduserer boosts som rager skyhøyt over resten av lydbildet. Ikke rart enkelte har opplevd at lyden får en resonant karakter når man forsøker å kansellere kanselleringer.... Legg forøvrig merke til at 1/3 plottet holder godt følge i bølgedalene ved enkelte lave frekvenser. Ikke bra det heller.
I god, hifi-nerdete ånd så tror jeg at vi i noen grad hører alt det som Farina sine plott viser til det motsatte er bevist og akseptert blant kresne hifi entusiaster. Jeg tror vi hører hele det variable forløpet i all sin skrekk og gru. Med fasedreininger og greier. Overshoots, kanselleringer og det som er. Det man ønsker er jo at alle toner gjengis med rett nivå og rett fase så lenge de varer. Men alt dette er ikke "in your face" problemer. Men snarere smårusk som vil prege sortnivået og perspektivistisk skarphet i et ellers velfungerende anlegg. Hvis man har klart å frekvensjustere anlegget på en fornuftig måte, vel å merke.
For å oppsummere: Vi hører alle toppene i kamfilteret. Og de aller fleste hører vi med uforminsket styrke. De fleste kanselleringer gir mye kraftigere lyd enn det frekvensresponsen skulle tyde på. Når man så glatter med 1/3 oktav så får kanselleringene uforlholdsmessig stor innflytelse på hvor den glatte kurven havner i forhold til kamfilteret. Derfor faller 1/3 oktavs kurven for mye. Dette allerede før vi tenker psykoakustikk.
Diverse maskeringseffekter gjør at vi rent psykoakustisk legger mye bedre merke til de kraftige enn de svake frekvensene. Og at vi legger bedre merke til de kraftige partier av svake frekvenser enn de svake partier av svake frekvenser. Alt dette gjør at det vår oppfattelse av lyden ligger mye tettere på toppen av kamfilteret enn det slike kurver pleier å vise.